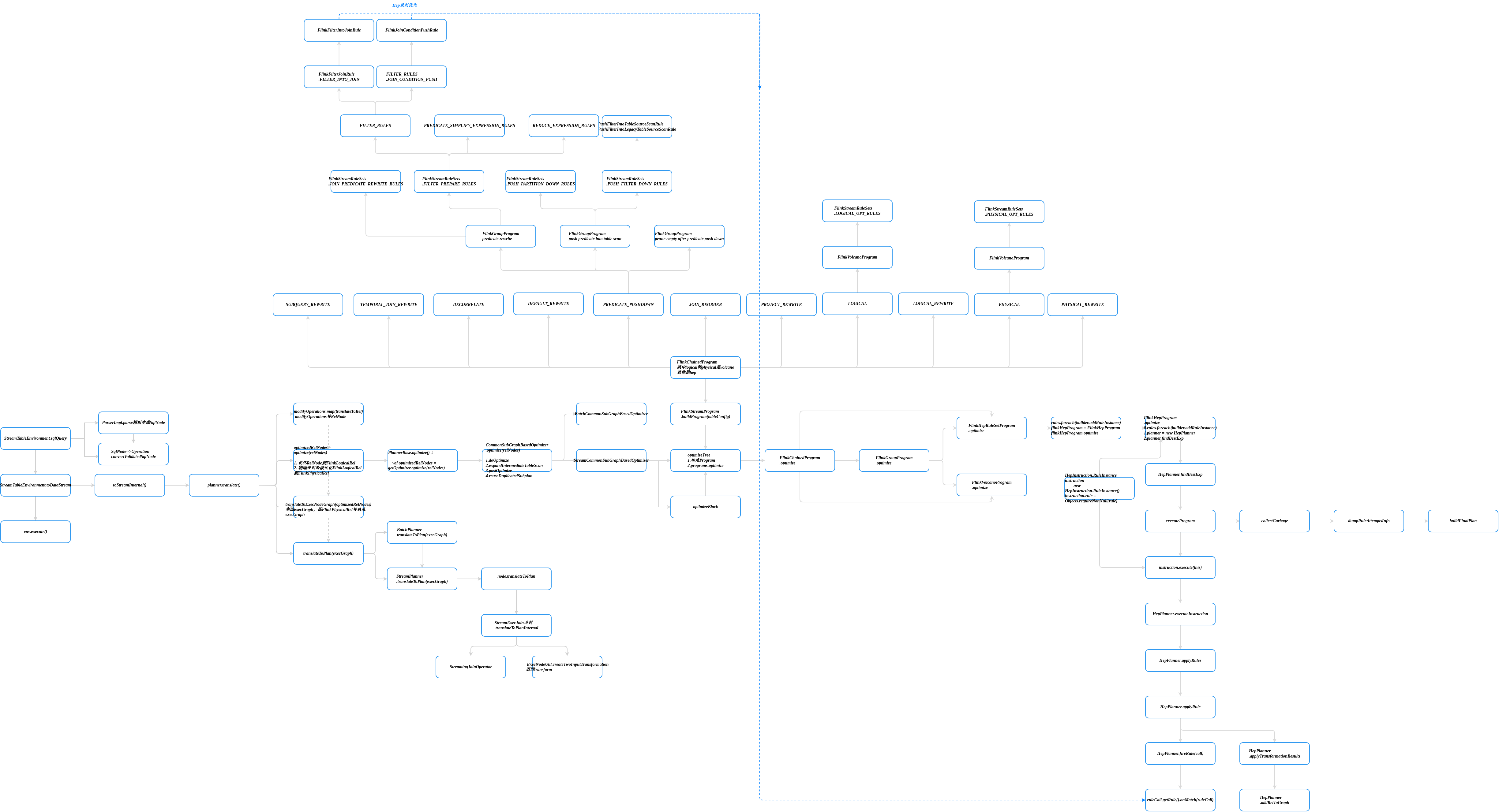
FlinkSQL流程图
 StreamSQLExample 示例代码
StreamSQLExample 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def main(args: Array[String]): Unit = {
// set up the Scala DataStream API
val env = StreamExecutionEnvironment.getExecutionEnvironment
// set up the Scala Table API
val tableEnv = StreamTableEnvironment.create(env)
val orderA =
env.fromCollection(Seq(Order(1L, "beer", 3), Order(1L, "diaper", 4), Order(3L, "rubber", 2)))
val orderB =
env.fromCollection(Seq(Order(2L, "pen", 3), Order(2L, "rubber", 3), Order(4L, "beer", 1)))
// convert the first DataStream to a Table object
// it will be used "inline" and is not registered in a catalog
val tableA = tableEnv.fromDataStream(orderA)
// convert the second DataStream and register it as a view
// it will be accessible under a name
tableEnv.createTemporaryView("TableB", orderB)
// union the two tables
val result = tableEnv.sqlQuery(s"""
|SELECT * FROM $tableA WHERE amount > 2
|UNION ALL
|SELECT * FROM TableB WHERE amount < 2
""".stripMargin)
// convert the Table back to an insert-only DataStream of type `Order`
tableEnv.toDataStream(result, classOf[Order]).print()
// after the table program is converted to a DataStream program,
// we must use `env.execute()` to submit the job
env.execute()
}
StreamTableEnvironment.sqlQuery
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public Table sqlQuery(String query) {
//将SQL解析成SqlNode,生成逻辑执行计划,并封装成Operation,普通select语句就是,PlannerQueryOperation
List<Operation> operations = getParser().parse(query);
if (operations.size() != 1) {
throw new ValidationException(
"Unsupported SQL query! sqlQuery() only accepts a single SQL query.");
}
Operation operation = operations.get(0);
if (operation instanceof QueryOperation && !(operation instanceof ModifyOperation)) {
return createTable((QueryOperation) operation);
} else {
throw new ValidationException(
"Unsupported SQL query! sqlQuery() only accepts a single SQL query of type "
+ "SELECT, UNION, INTERSECT, EXCEPT, VALUES, and ORDER_BY.");
}
}
- SQL解析阶段
生成AST(抽象语法树),将SQL转化为SqlNode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public List<Operation> parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
Optional<Operation> command = EXTENDED_PARSER.parse(statement);
if (command.isPresent()) {
return Collections.singletonList(command.get());
}
// parse the sql query
// use parseSqlList here because we need to support statement end with ';' in sql client.
//解析sql生成SqlNode,
SqlNodeList sqlNodeList = parser.parseSqlList(statement);
List<SqlNode> parsed = sqlNodeList.getList();
Preconditions.checkArgument(parsed.size() == 1, "only single statement supported");
return Collections.singletonList(
SqlToOperationConverter.convert(planner, catalogManager, parsed.get(0))
.orElseThrow(() -> new TableException("Unsupported query: " + statement)));
}
- 验证阶段,SqlNode –>SqlNode
``` public static Optionalconvert( FlinkPlannerImpl flinkPlanner, CatalogManager catalogManager, SqlNode sqlNode) { // validate the query //验证阶段,还是SqlNode final SqlNode validated = flinkPlanner.validate(sqlNode); return convertValidatedSqlNode(flinkPlanner, catalogManager, validated); }
1
3. 语义分析,生成逻辑计划树(SqlNode–>RelNode/RexNode)
// /** Convert a validated sql node to Operation. */ private static Optional
} //SqlToOperationConverter private Operation convertSqlQuery(SqlNode node) { return toQueryOperation(flinkPlanner, node); } //SqlToOperationConverter //生成relNode,并封装成PlannerQueryOperation private PlannerQueryOperation toQueryOperation(FlinkPlannerImpl planner, SqlNode validated) { // transform to a relational tree RelRoot relational = planner.rel(validated); return new PlannerQueryOperation(relational.project()); }
1
2
planner的实现类是FlinkPlannerImpl
//FlinkPlannerImpl def rel(validatedSqlNode: SqlNode): RelRoot = { rel(validatedSqlNode, getOrCreateSqlValidator())//FlinkCalciteSqlValidator } //FlinkPlannerImpl private def rel(validatedSqlNode: SqlNode, sqlValidator: FlinkCalciteSqlValidator) = { try { assert(validatedSqlNode != null) val sqlToRelConverter: SqlToRelConverter = createSqlToRelConverter(sqlValidator)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
sqlToRelConverter.convertQuery(validatedSqlNode, false, true)
// we disable automatic flattening in order to let composite types pass without modification
// we might enable it again once Calcite has better support for structured types
// root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true))
// TableEnvironment.optimize will execute the following
// root = root.withRel(RelDecorrelator.decorrelateQuery(root.rel))
// convert time indicators
// root = root.withRel(RelTimeIndicatorConverter.convert(root.rel, rexBuilder))
} catch {
case e: RelConversionException => throw new TableException(e.getMessage)
} } ``` 定义FlinkCalciteSqlValidator,SqlToRelConverter就是是Calcite的<br />SqlToRelConverter.convertQueryRecursive将SqlNode转RelNode ``` //SqlToRelConverter public RelRoot convertQuery(SqlNode query, boolean needsValidation, boolean top) {
if (needsValidation) {
query = this.validator.validate(query);
}
RelNode result = this.convertQueryRecursive(query, top, (RelDataType)null).rel;
if (top && isStream(query)) {
result = new LogicalDelta(this.cluster, ((RelNode)result).getTraitSet(), (RelNode)result);
}
RelCollation collation = RelCollations.EMPTY;
if (!query.isA(SqlKind.DML) && isOrdered(query)) {
collation = this.requiredCollation((RelNode)result);
}
this.checkConvertedType(query, (RelNode)result);
if (SQL2REL_LOGGER.isDebugEnabled()) {
SQL2REL_LOGGER.debug(RelOptUtil.dumpPlan("Plan after converting SqlNode to RelNode", (RelNode)result, SqlExplainFormat.TEXT, SqlExplainLevel.EXPPLAN_ATTRIBUTES));
}
RelDataType validatedRowType = this.validator.getValidatedNodeType(query);
List<RelHint> hints = new ArrayList();
if (query.getKind() == SqlKind.SELECT) {
SqlSelect select = (SqlSelect)query;
if (select.hasHints()) {
hints = SqlUtil.getRelHint(this.hintStrategies, select.getHints());
}
}
RelNode result = RelOptUtil.propagateRelHints((RelNode)result, false);
return RelRoot.of(result, validatedRowType, query.getKind()).withCollation(collation).withHints((List)hints); } ```
- 优化阶段(RelNode–>RelNode)
tableEnv.toDataStream(result, Order.class)
toStreamInternal–>planner.translate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
public <T> DataStream<T> toDataStream(Table table, Class<T> targetClass) {
Preconditions.checkNotNull(table, "Table must not be null.");
Preconditions.checkNotNull(targetClass, "Target class must not be null.");
if (targetClass == Row.class) {//targetClass==Order.class
// for convenience, we allow the Row class here as well
return (DataStream<T>) toDataStream(table);//这里
}
return toDataStream(table, DataTypes.of(targetClass));
}
//
public <T> DataStream<T> toDataStream(Table table, AbstractDataType<?> targetDataType) {
Preconditions.checkNotNull(table, "Table must not be null.");
Preconditions.checkNotNull(targetDataType, "Target data type must not be null.");
final SchemaTranslator.ProducingResult schemaTranslationResult =
SchemaTranslator.createProducingResult(
getCatalogManager().getDataTypeFactory(),
table.getResolvedSchema(),
targetDataType);
return toStreamInternal(table, schemaTranslationResult, ChangelogMode.insertOnly());
}
//
protected <T> DataStream<T> toStreamInternal(
Table table,
SchemaTranslator.ProducingResult schemaTranslationResult,
@Nullable ChangelogMode changelogMode) {
//省略其他代码,只看toStreamInternal
return toStreamInternal(table, modifyOperation);
}
//
protected <T> DataStream<T> toStreamInternal(Table table, ModifyOperation modifyOperation) {
//PlannerBase.translate
final List<Transformation<?>> transformations =
planner.translate(Collections.singletonList(modifyOperation));
final Transformation<T> transformation = getTransformation(table, transformations);
executionEnvironment.addOperator(transformation);
// Reconfigure whenever planner transformations are added
// We pass only the configuration to avoid reconfiguration with the rootConfiguration
executionEnvironment.configure(tableConfig.getConfiguration());
return new DataStream<>(executionEnvironment, transformation);
}
PlannerBase
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
beforeTranslation()
if (modifyOperations.isEmpty) {
return List.empty[Transformation[_]]
}
//这里是modifyOperations 有ExternalModifyOperation等,生成一个DataStreamTableSink
val relNodes = modifyOperations.map(translateToRel)
//1.优化RelNode到FlinkLogicalRel,
//2. 物理规则阶段优化FlinkLogicalRel到FlinkPhysicalRel
val optimizedRelNodes = optimize(relNodes)
//生成execGraph,即FlinkPhysicalRel转换成execGraph
val execGraph = translateToExecNodeGraph(optimizedRelNodes)
//生成物理执行计划,这里实现类StreamPlanner和BatchPlanner
val transformations = translateToPlan(execGraph)
afterTranslation()
transformations
}
PlannerBase逻辑执行计划优化
1.15版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private[flink] def optimize(relNodes: Seq[RelNode]): Seq[RelNode] = {
val optimizedRelNodes = getOptimizer.optimize(relNodes)//
require(optimizedRelNodes.size == relNodes.size)
optimizedRelNodes
}
//CommonSubGraphBasedOptimizer
override def optimize(roots: Seq[RelNode]): Seq[RelNode] = {
//
val sinkBlocks = doOptimize(roots)
val optimizedPlan = sinkBlocks.map {
block =>
val plan = block.getOptimizedPlan
require(plan != null)
plan
}
expandIntermediateTableScan(optimizedPlan)
}
1.16版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
override def optimize(roots: Seq[RelNode]): Seq[RelNode] = {
// resolve hints before optimizing
val joinHintResolver = new JoinHintResolver()
val resolvedHintRoots = joinHintResolver.resolve(toJava(roots))
// clear query block alias bef optimizing
val clearQueryBlockAliasResolver = new ClearQueryBlockAliasResolver
val resolvedAliasRoots = clearQueryBlockAliasResolver.resolve(resolvedHintRoots)
//doOptimize 两种实现流批
val sinkBlocks = doOptimize(resolvedAliasRoots)
val optimizedPlan = sinkBlocks.map {
block =>
val plan = block.getOptimizedPlan
require(plan != null)
plan
}
val expanded = expandIntermediateTableScan(optimizedPlan)
val postOptimizedPlan = postOptimize(expanded)
// Rewrite same rel object to different rel objects
// in order to get the correct dag (dag reuse is based on object not digest)
val shuttle = new SameRelObjectShuttle()
val relsWithoutSameObj = postOptimizedPlan.map(_.accept(shuttle))
// reuse subplan
SubplanReuser.reuseDuplicatedSubplan(relsWithoutSameObj, unwrapTableConfig(roots.head))
}
doOptimize由子类实现,流批分开:StreamCommonSubGraphBasedOptimizer,BatchCommonSubGraphBasedOptimizer
主要两个方法 optimizeTree ,optimizeBlock
StreamCommonSubGraphBasedOptimizer.doOptimize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
override protected def doOptimize(roots: Seq[RelNode]): Seq[RelNodeBlock] = {
val tableConfig = planner.getTableConfig
// build RelNodeBlock plan
val sinkBlocks = RelNodeBlockPlanBuilder.buildRelNodeBlockPlan(roots, tableConfig)
// infer trait properties for sink block
sinkBlocks.foreach {
sinkBlock =>
// don't require update before by default
sinkBlock.setUpdateBeforeRequired(false)
val miniBatchInterval: MiniBatchInterval =
if (tableConfig.get(ExecutionConfigOptions.TABLE_EXEC_MINIBATCH_ENABLED)) {
val miniBatchLatency =
tableConfig.get(ExecutionConfigOptions.TABLE_EXEC_MINIBATCH_ALLOW_LATENCY).toMillis
Preconditions.checkArgument(
miniBatchLatency > 0,
"MiniBatch Latency must be greater than 0 ms.",
null)
new MiniBatchInterval(miniBatchLatency, MiniBatchMode.ProcTime)
} else {
MiniBatchIntervalTrait.NONE.getMiniBatchInterval
}
sinkBlock.setMiniBatchInterval(miniBatchInterval)
}
if (sinkBlocks.size == 1) {
// If there is only one sink block, the given relational expressions are a simple tree
// (only one root), not a dag. So many operations (e.g. infer and propagate
// requireUpdateBefore) can be omitted to save optimization time.
val block = sinkBlocks.head
val optimizedTree = optimizeTree(
block.getPlan,
block.isUpdateBeforeRequired,
block.getMiniBatchInterval,
isSinkBlock = true)
block.setOptimizedPlan(optimizedTree)
return sinkBlocks
}
//optimizeBlock
// TODO FLINK-24048: Move changeLog inference out of optimizing phase
// infer modifyKind property for each blocks independently
sinkBlocks.foreach(b => optimizeBlock(b, isSinkBlock = true))
// infer and propagate updateKind and miniBatchInterval property for each blocks
sinkBlocks.foreach {
b =>
propagateUpdateKindAndMiniBatchInterval(
b,
b.isUpdateBeforeRequired,
b.getMiniBatchInterval,
isSinkBlock = true)
}
// clear the intermediate result
sinkBlocks.foreach(resetIntermediateResult)
// optimize recursively RelNodeBlock
sinkBlocks.foreach(b => optimizeBlock(b, isSinkBlock = true))
sinkBlocks
}
BatchCommonSubGraphBasedOptimizer.doOptimize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
override protected def doOptimize(roots: Seq[RelNode]): Seq[RelNodeBlock] = {
// build RelNodeBlock plan
val rootBlocks =
RelNodeBlockPlanBuilder.buildRelNodeBlockPlan(roots, planner.getTableConfig)
// optimize recursively RelNodeBlock
rootBlocks.foreach(optimizeBlock)
rootBlocks
}
private def optimizeBlock(block: RelNodeBlock): Unit = {
block.children.foreach {
child =>
if (child.getNewOutputNode.isEmpty) {
optimizeBlock(child)
}
}
val originTree = block.getPlan
val optimizedTree = optimizeTree(originTree)
optimizedTree match {
case _: LegacySink | _: Sink => // ignore
case _ =>
val name = createUniqueIntermediateRelTableName
val intermediateRelTable =
new IntermediateRelTable(Collections.singletonList(name), optimizedTree)
val newTableScan = wrapIntermediateRelTableToTableScan(intermediateRelTable, name)
block.setNewOutputNode(newTableScan)
block.setOutputTableName(name)
}
block.setOptimizedPlan(optimizedTree)
}
看下流的optimizeTree
StreamCommonSubGraphBasedOptimizer.optimizeTree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
private def optimizeTree(
relNode: RelNode,
updateBeforeRequired: Boolean,
miniBatchInterval: MiniBatchInterval,
isSinkBlock: Boolean): RelNode = {
val tableConfig = planner.getTableConfig
val calciteConfig = TableConfigUtils.getCalciteConfig(tableConfig)
//注意programs的构建FlinkStreamProgram.buildProgram
val programs = calciteConfig.getStreamProgram
.getOrElse(FlinkStreamProgram.buildProgram(tableConfig))
Preconditions.checkNotNull(programs)
val context = unwrapContext(relNode)
//FlinkChainedProgram
programs.optimize(
relNode,
new StreamOptimizeContext() {
override def isBatchMode: Boolean = false
override def getTableConfig: TableConfig = tableConfig
override def getFunctionCatalog: FunctionCatalog = planner.functionCatalog
override def getCatalogManager: CatalogManager = planner.catalogManager
override def getModuleManager: ModuleManager = planner.moduleManager
override def getRexFactory: RexFactory = context.getRexFactory
override def getFlinkRelBuilder: FlinkRelBuilder = planner.createRelBuilder
override def isUpdateBeforeRequired: Boolean = updateBeforeRequired
def getMiniBatchInterval: MiniBatchInterval = miniBatchInterval
override def needFinalTimeIndicatorConversion: Boolean = isSinkBlock
override def getClassLoader: ClassLoader = context.getClassLoader
}
)
}
这里的programs是FlinkStreamProgram.buildProgram生成的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
def buildProgram(tableConfig: ReadableConfig): FlinkChainedProgram[StreamOptimizeContext] = {
val chainedProgram = new FlinkChainedProgram[StreamOptimizeContext]()
// rewrite sub-queries to joins
chainedProgram.addLast(
SUBQUERY_REWRITE,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
// rewrite QueryOperationCatalogViewTable before rewriting sub-queries
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.TABLE_REF_RULES)
.build(),
"convert table references before rewriting sub-queries to semi-join"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.SEMI_JOIN_RULES)
.build(),
"rewrite sub-queries to semi-join"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.TABLE_SUBQUERY_RULES)
.build(),
"sub-queries remove"
)
// convert RelOptTableImpl (which exists in SubQuery before) to FlinkRelOptTable
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.TABLE_REF_RULES)
.build(),
"convert table references after sub-queries removed"
)
.build()
)
// rewrite special temporal join plan
chainedProgram.addLast(
TEMPORAL_JOIN_REWRITE,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.EXPAND_PLAN_RULES)
.build(),
"convert correlate to temporal table join"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.POST_EXPAND_CLEAN_UP_RULES)
.build(),
"convert enumerable table scan"
)
.build()
)
// query decorrelation
chainedProgram.addLast(
DECORRELATE,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
// rewrite before decorrelation
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PRE_DECORRELATION_RULES)
.build(),
"pre-rewrite before decorrelation"
)
.addProgram(new FlinkDecorrelateProgram)
.build()
)
// default rewrite, includes: predicate simplification, expression reduction, window
// properties rewrite, etc.
chainedProgram.addLast(
DEFAULT_REWRITE,
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.DEFAULT_REWRITE_RULES)
.build()
)
// rule based optimization: push down predicate(s) in where clause, so it only needs to read
// the required data
chainedProgram.addLast(
PREDICATE_PUSHDOWN,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder
.newBuilder[StreamOptimizeContext]
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.JOIN_PREDICATE_REWRITE_RULES)
.build(),
"join predicate rewrite"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.FILTER_PREPARE_RULES)
.build(),
"filter rules"
)
.setIterations(5)
.build(),
"predicate rewrite"
)
.addProgram(
// PUSH_PARTITION_DOWN_RULES should always be in front of PUSH_FILTER_DOWN_RULES
// to prevent PUSH_FILTER_DOWN_RULES from consuming the predicates in partitions
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_PARTITION_DOWN_RULES)
.build(),
"push down partitions into table scan"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_FILTER_DOWN_RULES)
.build(),
"push down filters into table scan"
)
.build(),
"push predicate into table scan"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PRUNE_EMPTY_RULES)
.build(),
"prune empty after predicate push down"
)
.build()
)
// join reorder
if (tableConfig.get(OptimizerConfigOptions.TABLE_OPTIMIZER_JOIN_REORDER_ENABLED)) {
chainedProgram.addLast(
JOIN_REORDER,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.JOIN_REORDER_PREPARE_RULES)
.build(),
"merge join into MultiJoin"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.JOIN_REORDER_RULES)
.build(),
"do join reorder"
)
.build()
)
}
// project rewrite
chainedProgram.addLast(
PROJECT_REWRITE,
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PROJECT_RULES)
.build()
)
// optimize the logical plan
chainedProgram.addLast(
LOGICAL,
FlinkVolcanoProgramBuilder.newBuilder
.add(FlinkStreamRuleSets.LOGICAL_OPT_RULES)
.setRequiredOutputTraits(Array(FlinkConventions.LOGICAL))
.build()
)
// logical rewrite
chainedProgram.addLast(
LOGICAL_REWRITE,
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.LOGICAL_REWRITE)
.build()
)
// convert time indicators
chainedProgram.addLast(TIME_INDICATOR, new FlinkRelTimeIndicatorProgram)
// optimize the physical plan
chainedProgram.addLast(
PHYSICAL,
FlinkVolcanoProgramBuilder.newBuilder
.add(FlinkStreamRuleSets.PHYSICAL_OPT_RULES)
.setRequiredOutputTraits(Array(FlinkConventions.STREAM_PHYSICAL))
.build()
)
// physical rewrite
chainedProgram.addLast(
PHYSICAL_REWRITE,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
// add a HEP program for watermark transpose rules to make this optimization deterministic
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.WATERMARK_TRANSPOSE_RULES)
.build(),
"watermark transpose"
)
.addProgram(new FlinkChangelogModeInferenceProgram, "Changelog mode inference")
.addProgram(
new FlinkMiniBatchIntervalTraitInitProgram,
"Initialization for mini-batch interval inference")
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.TOP_DOWN)
.add(FlinkStreamRuleSets.MINI_BATCH_RULES)
.build(),
"mini-batch interval rules"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PHYSICAL_REWRITE)
.build(),
"physical rewrite"
)
.build()
)
chainedProgram
}
可以看出来是一个链组成的,看定义大概有
1
2
3
4
5
6
7
8
9
10
11
12
val SUBQUERY_REWRITE = "subquery_rewrite"
val TEMPORAL_JOIN_REWRITE = "temporal_join_rewrite"
val DECORRELATE = "decorrelate"
val DEFAULT_REWRITE = "default_rewrite"
val PREDICATE_PUSHDOWN = "predicate_pushdown"
val JOIN_REORDER = "join_reorder"
val PROJECT_REWRITE = "project_rewrite"
val LOGICAL = "logical"
val LOGICAL_REWRITE = "logical_rewrite"
val TIME_INDICATOR = "time_indicator"
val PHYSICAL = "physical"
val PHYSICAL_REWRITE = "physical_rewrite"
FlinkChainedProgram.optimize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def optimize(root: RelNode, context: OC): RelNode = {
programNames.foldLeft(root) {
(input, name) =>
val program = get(name).getOrElse(throw new TableException(s"This should not happen."))
val start = System.currentTimeMillis()
// program是FlinkOptimizeProgram
//FlinkOptimizeProgram子类由FlinkHepProgram或者FlinkVolcanoProgram等
val result = program.optimize(input, context)
val end = System.currentTimeMillis()
if (LOG.isDebugEnabled) {
LOG.debug(
s"optimize $name cost ${end - start} ms.\n" +
s"optimize result: \n${FlinkRelOptUtil.toString(result)}")
}
result
}
}
programNames可以看出是所有的program列表遍历一遍,以PREDICATE_PUSHDOWN为例,其定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
// rule based optimization: push down predicate(s) in where clause, so it only needs to read
// the required data
chainedProgram.addLast(
PREDICATE_PUSHDOWN,
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder
.newBuilder[StreamOptimizeContext]
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.JOIN_PREDICATE_REWRITE_RULES)
.build(),
"join predicate rewrite"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.FILTER_PREPARE_RULES)
.build(),
"filter rules"
)
.setIterations(5)
.build(),
"predicate rewrite"
)
.addProgram(
// PUSH_PARTITION_DOWN_RULES should always be in front of PUSH_FILTER_DOWN_RULES
// to prevent PUSH_FILTER_DOWN_RULES from consuming the predicates in partitions
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_PARTITION_DOWN_RULES)
.build(),
"push down partitions into table scan"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_FILTER_DOWN_RULES)
.build(),
"push down filters into table scan"
)
.build(),
"push predicate into table scan"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PRUNE_EMPTY_RULES)
.build(),
"prune empty after predicate push down"
)
.build()
)
这个也是多条,包括三个组”predicate rewrite”
FlinkStreamRuleSets.JOIN_PREDICATE_REWRITE_RULES
FlinkStreamRuleSets.FILTER_PREPARE_RULES
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
.addProgram(
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder
.newBuilder[StreamOptimizeContext]
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.JOIN_PREDICATE_REWRITE_RULES)
.build(),
"join predicate rewrite"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_COLLECTION)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.FILTER_PREPARE_RULES)
.build(),
"filter rules"
)
.setIterations(5)
.build(),
"predicate rewrite"
)
push predicate into table scan
FlinkStreamRuleSets.PUSH_PARTITION_DOWN_RULES
FlinkStreamRuleSets.PUSH_FILTER_DOWN_RULES
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
.addProgram(
// PUSH_PARTITION_DOWN_RULES should always be in front of PUSH_FILTER_DOWN_RULES
// to prevent PUSH_FILTER_DOWN_RULES from consuming the predicates in partitions
FlinkGroupProgramBuilder
.newBuilder[StreamOptimizeContext]
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_PARTITION_DOWN_RULES)
.build(),
"push down partitions into table scan"
)
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PUSH_FILTER_DOWN_RULES)
.build(),
"push down filters into table scan"
)
.build(),
"push predicate into table scan"
)
prune empty after predicate push down
FlinkStreamRuleSets.PRUNE_EMPTY_RULES
1
2
3
4
5
6
7
8
9
.addProgram(
FlinkHepRuleSetProgramBuilder.newBuilder
.setHepRulesExecutionType(HEP_RULES_EXECUTION_TYPE.RULE_SEQUENCE)
.setHepMatchOrder(HepMatchOrder.BOTTOM_UP)
.add(FlinkStreamRuleSets.PRUNE_EMPTY_RULES)
.build(),
"prune empty after predicate push down"
)
.build()
逻辑执行计划
LOGICAL_CONVERTERS负责转换RelNode到FlinkLogicalRel转换
1
2
3
4
5
6
7
8
9
/** RuleSet to do logical optimize for stream */
val LOGICAL_OPT_RULES: RuleSet = RuleSets.ofList(
(
FILTER_RULES.asScala ++
PROJECT_RULES.asScala ++
PRUNE_EMPTY_RULES.asScala ++
LOGICAL_RULES.asScala ++
LOGICAL_CONVERTERS.asScala//转换RelNode -->FlinkLogicalRel
).asJava)
LOGICAL_CONVERTERS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/** RuleSet to translate calcite nodes to flink nodes */
private val LOGICAL_CONVERTERS: RuleSet = RuleSets.ofList(
// translate to flink logical rel nodes
FlinkLogicalAggregate.STREAM_CONVERTER,
FlinkLogicalTableAggregate.CONVERTER,
FlinkLogicalOverAggregate.CONVERTER,
FlinkLogicalCalc.CONVERTER,
FlinkLogicalCorrelate.CONVERTER,
FlinkLogicalJoin.CONVERTER,
FlinkLogicalSort.STREAM_CONVERTER,
FlinkLogicalUnion.CONVERTER,
FlinkLogicalValues.CONVERTER,
FlinkLogicalTableSourceScan.CONVERTER,
FlinkLogicalLegacyTableSourceScan.CONVERTER,
FlinkLogicalTableFunctionScan.CONVERTER,
FlinkLogicalDataStreamTableScan.CONVERTER,
FlinkLogicalIntermediateTableScan.CONVERTER,
FlinkLogicalExpand.CONVERTER,
FlinkLogicalRank.CONVERTER,
FlinkLogicalWatermarkAssigner.CONVERTER,
FlinkLogicalWindowAggregate.CONVERTER,
FlinkLogicalWindowTableAggregate.CONVERTER,
FlinkLogicalSnapshot.CONVERTER,
FlinkLogicalMatch.CONVERTER,
FlinkLogicalSink.CONVERTER,
FlinkLogicalLegacySink.CONVERTER
)
比如FlinkLogicalJoinConverter负责join的转换
即join RelNode–>FlinkLogicalJoin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/** Support all joins. */
private class FlinkLogicalJoinConverter
extends ConverterRule(
classOf[LogicalJoin],
Convention.NONE,
FlinkConventions.LOGICAL,
"FlinkLogicalJoinConverter") {
override def convert(rel: RelNode): RelNode = {
val join = rel.asInstanceOf[LogicalJoin]
val newLeft = RelOptRule.convert(join.getLeft, FlinkConventions.LOGICAL)
val newRight = RelOptRule.convert(join.getRight, FlinkConventions.LOGICAL)
FlinkLogicalJoin.create(newLeft, newRight, join.getCondition, join.getHints, join.getJoinType)
}
}
object FlinkLogicalJoin {
val CONVERTER: ConverterRule = new FlinkLogicalJoinConverter
//创建FlinkLogicalJoin
def create(
left: RelNode,
right: RelNode,
conditionExpr: RexNode,
hints: JList[RelHint],
joinType: JoinRelType): FlinkLogicalJoin = {
val cluster = left.getCluster
val traitSet = cluster.traitSetOf(FlinkConventions.LOGICAL).simplify()
new FlinkLogicalJoin(cluster, traitSet, left, right, conditionExpr, hints, joinType)
}
}
同理经过PHYSICAL,PHYSICAL_REWRITE优化转换后,得到FlinkPhysicalRel
比如StreamPhysicalDataStreamScanRule转换为StreamPhysicalDataStreamScan
StreamPhysicalTableSourceScanRule转换位StreamPhysicalChangelogNormalize
之后FlinkPhysicalRel转换为ExecNodeGraph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private[flink] def translateToExecNodeGraph(
optimizedRelNodes: Seq[RelNode],
isCompiled: Boolean): ExecNodeGraph = {
val nonPhysicalRel = optimizedRelNodes.filterNot(_.isInstanceOf[FlinkPhysicalRel])
if (nonPhysicalRel.nonEmpty) {
throw new TableException(
"The expected optimized plan is FlinkPhysicalRel plan, " +
s"actual plan is ${nonPhysicalRel.head.getClass.getSimpleName} plan.")
}
require(optimizedRelNodes.forall(_.isInstanceOf[FlinkPhysicalRel]))
// convert FlinkPhysicalRel DAG to ExecNodeGraph
val generator = new ExecNodeGraphGenerator()
//优化后的节点生成execGraph
val execGraph =
generator.generate(optimizedRelNodes.map(_.asInstanceOf[FlinkPhysicalRel]), isCompiled)
// process the graph
val context = new ProcessorContext(this)
val processors = getExecNodeGraphProcessors
processors.foldLeft(execGraph)((graph, processor) => processor.process(graph, context))
}
最后ExecNodeGraph生成transformations
StreamPlanner为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//StreamPlanner
override protected def translateToPlan(execGraph: ExecNodeGraph): util.List[Transformation[_]] = {
beforeTranslation()
val planner = createDummyPlanner()
val transformations = execGraph.getRootNodes.map {
case node: StreamExecNode[_] => node.translateToPlan(planner)//ExecNodeBase
case _ =>
throw new TableException(
"Cannot generate DataStream due to an invalid logical plan. " +
"This is a bug and should not happen. Please file an issue.")
}
afterTranslation()
transformations
}
ExecNodeBase
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public final Transformation<T> translateToPlan(Planner planner) {
if (transformation == null) {
//translateToPlanInternal有子类实现,比如StreamExecJoin,StreamExecWindowJoin
transformation =
translateToPlanInternal(
(PlannerBase) planner,
new ExecNodeConfig(
((PlannerBase) planner).getTableConfig(), persistedConfig));
if (this instanceof SingleTransformationTranslator) {
if (inputsContainSingleton()) {
transformation.setParallelism(1);
transformation.setMaxParallelism(1);
}
}
}
return transformation;
}
translateToPlanInternal由具体子类实现,比如StreamExecJoin,StreamExecWindowJoin
FlinkBatchProgram
FlinkStreamProgram